Behaviour = f(Stimulus)
The question then is how we find out what this function is. If the data is quite simple we can get some idea by plotting all the recorded stimuli against the response they produced, e.g.

Here we only have one stimulus and one response, so it's quite easy to plot the data and see a pattern. Clearly the behaviour increases in line with the size of the stimulus, and the relationship seems close to a straight line. But of course the points don't lie exactly on a straight line, that would be too easy! We could try and fit a function that passed through every point exactly, but that would be rather complicated and wouldn't really add to our understanding...

Too complicated
Instead we can choose to see some of the variation from point to point as noise. Noise is simply variation in the observed behaviour that we either can't predict or are not interested in predicting. It might be due to inaccuracy in the measuring equipment, variation in the environment that we do not measure, or simply "biological variation" i.e. the fact that animals often act quite unpredictably!
Allowing for the existence of noise, we can now see the observed behaviour as the sum of predictable and unpredictable parts. The predictable part is given by the function we want to estimate, while the unpredictable part is the noise, also known as the residual
Behaviour = f(Stimulus) + residual
Generally we want to predict as much about the animal's behaviour as possible, so we want to minimise the unpredictable part of this equation, and maximise the predictable part. This means we need to find a function that minimises the distance between f(Stimulus) and the observed Behaviour. This is the justification behind least-squares regression (LSR).
To see LSR in action, lets try to fit a straight line to the data we saw above. Doubtless you will have had to do this in a maths lesson at some point, using some long formula to calculate the right line. Here instead we are going to examine exactly what we're doing when we try to fit a straight line to the data. For simplicity, lets say that our straight line will go through the origin (0, 0). So the equation of any straight line we might try is:
Behaviour = Stimulus × Slope + residual
If we imagine trying different slopes, we can see by eye that some are clearly better than others...

Good and bad straight lines
But why are some lines better than others? Because they 'go through the data better' - in other words they minimise the overall distance between the line and the data points. This can be measured by taking the sum of square errors (SSE) - a fancy way of saying 'measure the distance from the line to each data point, square each distance and add them all together'
SSE = r12 + r22 + r32 + r42 ... + r102
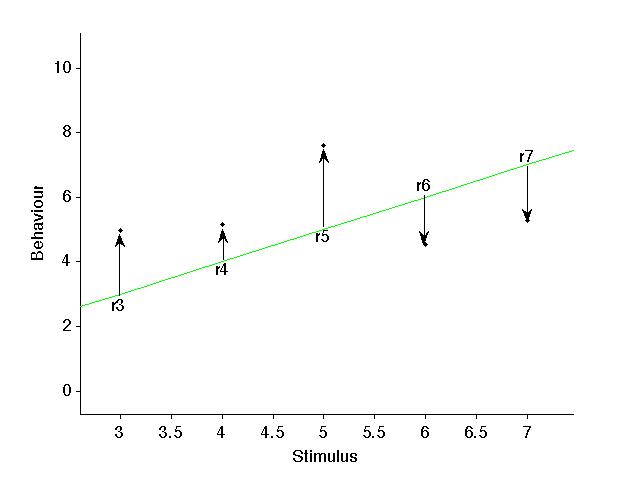
Measuring the errors
The important thing to realise is that the SSE quantifies how good the fit is, and that there is a value of SSE for every possible slope. The task of least-squares regression is to find the slope that minimises the SSE. But note that there is no slope that is "right" - we're just trying to find the one that is least wrong.

Every slope has its own quality of fit
Here the best fit line is found to have a slope of about 1.1, which is close the the slope of 1 that I used to make the data. Notice how the SSE (the total error) gets bigger as we move away from the best fit - making the line either steeper or shallower increases the error, which means that the fit is worse.
By seeing how quickly the fit gets worse when we change the slope we can estimate how certain we are about the best fit - if there is a wide area where the SSE is almost the same at the bottom then there are lots of slopes that are almost-as-good as the best line, which tells us that the data isn't enough to estimate the function well.
It is important to see that we could find the best slope without using a special formula. We could simply use trial and error, calculating the SSE for one slope, then another, moving in the same direction if the SSE improves and going back if it gets worse. Or we could do what I did to plot that figure and simply try lots of possible values of the slope and find the SSE for each one. When we start fitting more complicated functions we won't always have a nice neat formula that tells us what the best fit will be.
In the next post we'll look at how linear regression can be used for more than one stimulus and how we can fit non-linear functions.
No comments:
Post a Comment